Forest monitoring is critical for climate change mitigation. However, existing global tree height maps provide only static snapshots and do not capture temporal forest dynamics, which are essential for accurate carbon accounting. We introduce ECHOSAT, a global and temporally consistent tree height map at 10 m resolution spanning multiple years. To this end, we resort to multi-sensor satellite data to train a specialized vision transformer model, which performs pixel-level temporal regression. A self-supervised growth loss regularizes the predictions to follow growth curves that are in line with natural tree development, including gradual height increases over time, but also abrupt declines due to forest loss events such as fires. Our experimental evaluation shows that our model improves state-of-the-art accuracies in the context of single-year predictions. We also provide the first global-scale height map that accurately quantifies tree growth and disturbances over time. We expect ECHOSAT to advance global efforts in carbon monitoring and disturbance assessment.
@article{pauls2026echosat,title={ECHOSAT: Estimating Canopy Height Over Space And Time},author={Pauls, Jan and Schr{\"o}dter, Karsten and Ligensa, Sven and Schwartz, Martin and Turan, Berkant and Zimmer, Max and Saatchi, Sassan and Pokutta, Sebastian and Ciais, Philippe and Gieseke, Fabian},year={2026},}
2025
ICML 2025 Workshop
Neural Concept Verifier: Scaling Prover-Verifier Games Via Concept Encodings
Berkant Turan, Suhrab Asadulla, David Steinmann, Kristian Kersting, and 2 more authors
In Actionable Interpretability Workshop at ICML, 2025
While Prover-Verifier Games (PVGs) offer a promising path toward verifiability in nonlinear classification models, they have not yet been applied to complex inputs such as high-dimensional images. Conversely, expressive concept encodings effectively allow to translate such data into interpretable concepts but are often utilised in the context of low-capacity linear predictors. In this work, we push towards real-world verifiability by combining the strengths of both approaches. We introduce Neural Concept Verifier (NCV), a unified framework combining PVGs for formal verifiability with concept encodings to handle complex, high-dimensional inputs in an interpretable way. NCV achieves this by utilizing recent minimally supervised concept discovery models to extract structured concept encodings from raw inputs. A prover then selects a subset of these encodings, which a verifier, implemented as a nonlinear predictor, uses exclusively for decision-making. Our evaluations show that NCV outperforms classic concept-based models and pixel-based PVG classifier baselines on high-dimensional, logically complex datasets and helps mitigate shortcut behavior. Overall, we demonstrate NCV as a promising step toward concept-level, verifiable AI.
@inproceedings{turan2025neuralconceptverifier,title={Neural Concept Verifier: Scaling Prover-Verifier Games Via Concept Encodings},author={Turan, Berkant and Asadulla, Suhrab and Steinmann, David and Kersting, Kristian and Stammer, Wolfgang and Pokutta, Sebastian},booktitle={Actionable Interpretability Workshop at ICML},year={2025},}
ICML 2025
Capturing Temporal Dynamics in Large-Scale Canopy Tree Height Estimation
Jan Pauls*, Max Zimmer*, Berkant Turan*, Sassan Saatchi, and 3 more authors
In International Conference on Machine Learning (ICML), 2025
With the rise in global greenhouse gas emissions, accurate large-scale tree canopy height maps are essential for understanding forest structure, estimating above-ground biomass, and monitoring ecological disruptions. To this end, we present a novel approach to generate large-scale, high-resolution canopy height maps over time. Our model accurately predicts canopy height over multiple years given Sentinel-1 composite and Sentinel 2 time series satellite data. Using GEDI LiDAR data as the ground truth for training the model, we present the first 10m resolution temporal canopy height map of the European continent for the period 2019-2022. As part of this product, we also offer a detailed canopy height map for 2020, providing more precise estimates than previous studies. Our pipeline and the resulting temporal height map are publicly available, enabling comprehensive large-scale monitoring of forests and, hence, facilitating future research and ecological analyses.
@inproceedings{pauls2025capturing,title={Capturing Temporal Dynamics in Large-Scale Canopy Tree Height Estimation},author={Pauls*, Jan and Zimmer*, Max and Turan*, Berkant and Saatchi, Sassan and Ciais, Philippe and Pokutta, Sebastian and Gieseke, Fabian},booktitle={International Conference on Machine Learning (ICML)},year={2025},}
NeurIPS 2025
The Good, the Bad and the Ugly: Meta-Analysis of Watermarks, Transferable Attacks and Adversarial Defenses
Grzegorz Głuch, Berkant Turan, Sai Ganesh Nagarajan, and Sebastian Pokutta
In Conference on Neural Information Processing Systems (NeurIPS), 2025
We formalize and extend existing definitions of backdoor-based watermarks and adversarial defenses as interactive protocols between two players. The existence of these schemes is inherently tied to the learning tasks for which they are designed. Our main result shows that for almost every learning task, at least one of the two – a watermark or an adversarial defense – exists. The term “almost every” indicates that we also identify a third, counterintuitive but necessary option, i.e., a scheme we call a transferable attack. By transferable attack, we refer to an efficient algorithm computing queries that look indistinguishable from the data distribution and fool all efficient defenders. To this end, we prove the necessity of a transferable attack via a construction that uses a cryptographic tool called homomorphic encryption. Furthermore, we show that any task that satisfies our notion of a transferable attack implies a cryptographic primitive, thus requiring the underlying task to be computationally complex. These two facts imply an “equivalence” between the existence of transferable attacks and cryptography. Finally, we show that the class of tasks of bounded VC-dimension has an adversarial defense, and a subclass of them has a watermark.
@inproceedings{gluch2025_goodbadugly,title={The Good, the Bad and the Ugly: Meta-Analysis of Watermarks, Transferable Attacks and Adversarial Defenses},author={Głuch, Grzegorz and Turan, Berkant and Nagarajan, Sai Ganesh and Pokutta, Sebastian},year={2025},booktitle={Conference on Neural Information Processing Systems (NeurIPS)},primaryclass={cs.LG},}
2024
ICML2024 Workshop
Unified Taxonomy in AI Safety: Watermarks, Adversarial Defenses, and Transferable Attacks
Grzegorz Gluch, Sai Ganesh Nagarajan, and Berkant Turan
ICML 2024 Workshop on Theoretical Foundations of Foundation Models (TF2M), 2024
As AI becomes omnipresent in today’s world, it is crucial to study the safety aspects of learning, such as guaranteed watermarking capabilities and defenses against adversarial attacks. In prior works, these properties were generally studied separately and empirically barring a few exceptions. Meanwhile, strong forms of adversarial attacks that are transferable had been developed (empirically) for discriminative DNNs (Liu et al., 2016) and LLMs (Zou et al., 2023). In this ever-evolving landscape of attacks and defenses, we initiate the formal study of watermarks, defenses, and transferable attacks for classification, under a unified framework, by having two time-bounded players participate in an interactive protocol. Consequently, we show that for every learning task, at least one of the three schemes exists. Importantly, our results cover regimes where VC theory is not necessarily applicable. Finally we provide provable examples of the three schemes and show that transferable attacks exist only in regimes beyond bounded VC dimension. The example we give is a nontrivial construction based on cryptographic tools, i.e. homomorphic encryption.
@article{gluch_taxonomy_2024,title={Unified {T}axonomy in {AI} {S}afety: {W}atermarks, {A}dversarial {D}efenses, and {T}ransferable {A}ttacks},author={Gluch, Grzegorz and Nagarajan, Sai Ganesh and Turan, Berkant},journal={ICML 2024 Workshop on Theoretical Foundations of Foundation Models (TF2M)},year={2024},}
AISTATS 2024
Interpretability Guarantees with Merlin-Arthur Classifiers
Stephan Wäldchen, Kartikey Sharma, Berkant Turan, Max Zimmer, and 1 more author
In Proceedings of The 27th International Conference on Artificial Intelligence and Statistics (AISTATS), 2024
We propose an interactive multi-agent classifier that provides provable interpretability guarantees even for complex agents such as neural networks. These guarantees consist of lower bounds on the mutual information between selected features and the classification decision. Our results are inspired by the Merlin-Arthur protocol from Interactive Proof Systems and express these bounds in terms of measurable metrics such as soundness and completeness. Compared to existing interactive setups, we rely neither on optimal agents nor on the assumption that features are distributed independently. Instead, we use the relative strength of the agents as well as the new concept of Asymmetric Feature Correlation which captures the precise kind of correlations that make interpretability guarantees difficult. We evaluate our results on two small-scale datasets where high mutual information can be verified explicitly.
@inproceedings{pmlr-v238-waldchen24a,title={ Interpretability Guarantees with {M}erlin-{A}rthur Classifiers },author={W\"{a}ldchen, Stephan and Sharma, Kartikey and Turan, Berkant and Zimmer, Max and Pokutta, Sebastian},booktitle={Proceedings of The 27th International Conference on Artificial Intelligence and Statistics (AISTATS)},pages={1963--1971},year={2024},editor={Dasgupta, Sanjoy and Mandt, Stephan and Li, Yingzhen},volume={238},series={Proceedings of Machine Learning Research},publisher={PMLR},}
2023
Doc. Consortium
Extending Merlin-Arthur Classifiers for Improved Interpretability
Berkant Turan
In Joint Proceedings of the xAI-2023 Late-breaking Work, Demos and Doctoral Consortium, co-located with the 1st World Conference on eXplainable Artificial Intelligence (xAI-2023), Jul 2023
In my doctoral research, I aim to address the interpretability challenges associated with deep learning by extending the Merlin-Arthur Classifier framework. This novel approach employs a pair of feature selectors, including an adversarial player, to generate informative saliency maps. My research focuses on enhancing the classifier’s performance and exploring its applicability to complex datasets, including a recently established human benchmark for detecting pathologies in X-ray images. Tackling the min-max optimization challenge inherent in the Merlin-Arthur Classifier for high-dimensional data, I will explore and apply diverse stabilization strategies to bolster the framework’s robustness and training stability. Finally, the goal is to expand the framework beyond pixel-level saliency maps to encompass modalities, such as text and learned feature spaces, fostering a comprehensive understanding of interpretability across various domains and data types.
@inproceedings{TuranConsortium2023,title={Extending Merlin-Arthur Classifiers for Improved Interpretability},author={Turan, Berkant},booktitle={Joint Proceedings of the xAI-2023 Late-breaking Work, Demos and Doctoral Consortium, co-located with the 1st World Conference on eXplainable Artificial Intelligence (xAI-2023)},pages={193-200},year={2023},organization={Springer},address={Lisbon, Portugal},month=jul,}
2022
Msc Thesis
Robustness of Hybrid Discriminative-Generative Models
@mastersthesis{Turan2022Msc,title={Robustness of Hybrid Discriminative-Generative Models},author={Turan, Berkant},year={2022},school={Technical University of Berlin},type={mastersthesis},}
2018
Bsc Thesis
Modeling and Simulation of Convective Flows in the Outer Earth’s Core using the Finite Element Method
@bachelorsthesis{Turan2018Bsc,title={Modeling and Simulation of Convective Flows in the Outer Earth's Core using the Finite Element Method},author={Turan, Berkant},year={2018},month=oct,school={Technical University of Berlin},type={mastersthesis},}
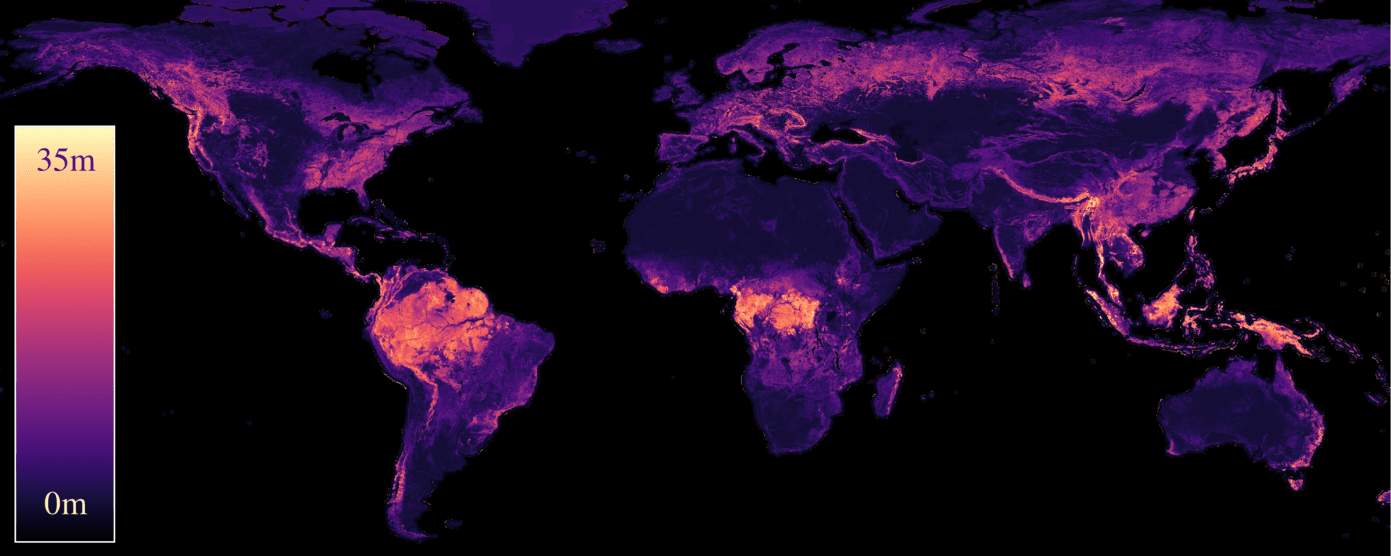 Preprint
Preprint
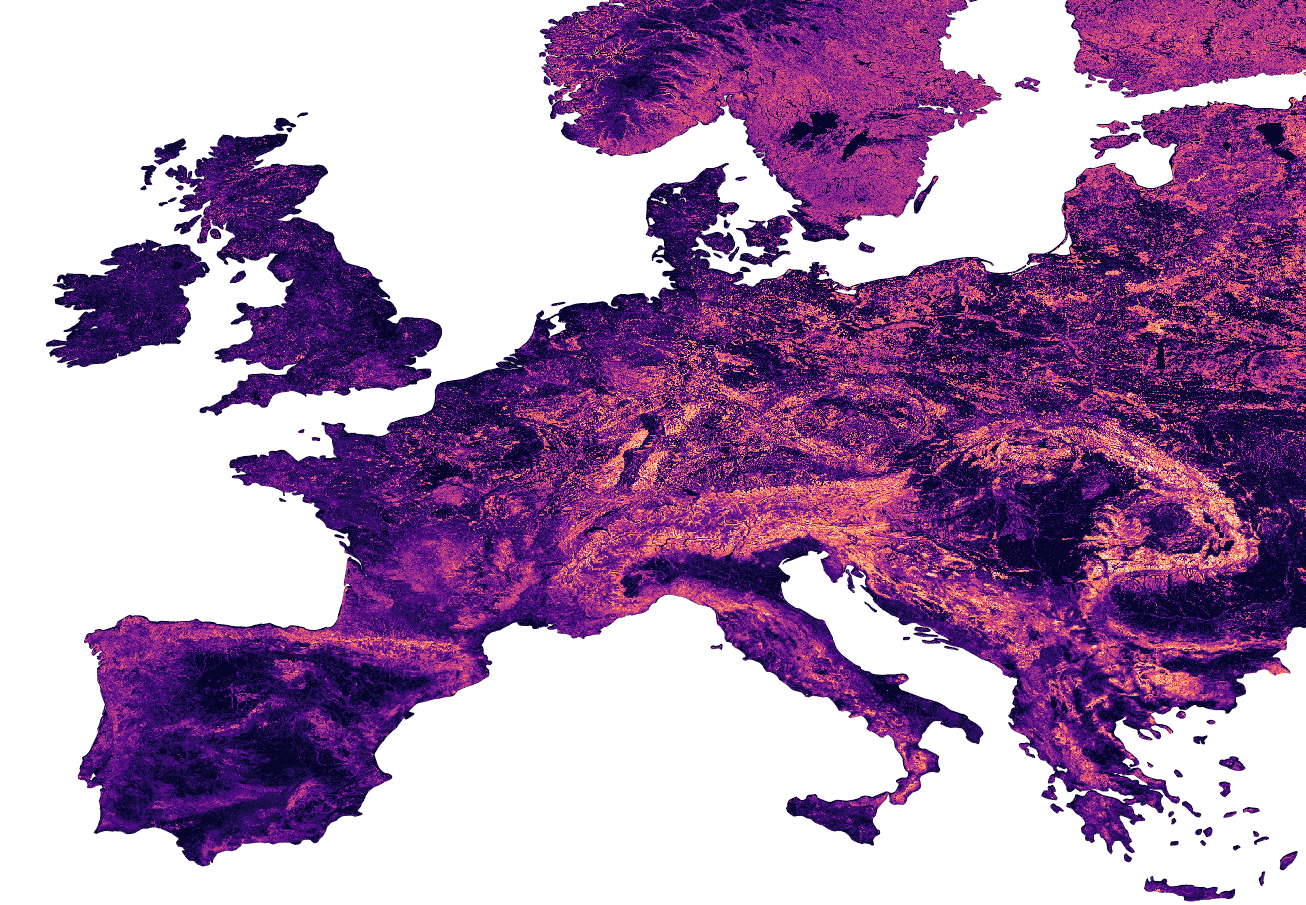 ICML 2025Capturing Temporal Dynamics in Large-Scale Canopy Tree Height EstimationIn International Conference on Machine Learning (ICML), 2025* Equal contribution
ICML 2025Capturing Temporal Dynamics in Large-Scale Canopy Tree Height EstimationIn International Conference on Machine Learning (ICML), 2025* Equal contribution




 Doc. Consortium
Doc. Consortium
